(投稿日:2024/8/23)
Webサイトは幾つものWebページで構成されています。そのWebページは、サーバからブラウザにどのように届いて、どのようにして表示されるのでしょうか。
例えば、以下のURLで表されるWebページがあるとします。
https://www.feedtailor.jp/sample.html
ブラウザにこのURLを入力した時、ページが表示されるまでの間に何がどのような順番で起こっているか「正確に」説明できるでしょうか?
これは掘り下げれば幾らでも掘り下げられる壮大なテーマで、行き着く先は「WiFi上の無線通信パケットの中身」や「PCやサーバ内電気回路での電圧変化」みたいな話になります。
が、ここではWebサイトの構築や運用という視点で知っておくと良い深さまでにとどめて解説します。
そもそもブラウザとは何なのか
まれに「ブラウザにURLを入力したら、そのWebページの完成形がブラウザに届く」と捉えている方がいます。例えるなら、印刷されたA4ビラをブラウザが受け取ってそれを表示しているのだ…という解釈ですね。

これは残念ながら完全な誤りです。この誤解は、印刷系の仕事をバックグラウンドに持つWebサイト関係者の方に多い気がします。
実は、Webサイトを見る時のブラウザ挙動を極限までシンプルに書くと、
- (1) URLで指定された「モノ」だけを取得して表示する
- (2) その「モノ」がHTMLファイルなら、HTMLに関連するファイルも取得して反映する
となります。分かり易さのために別の例を出しますが、例えば、
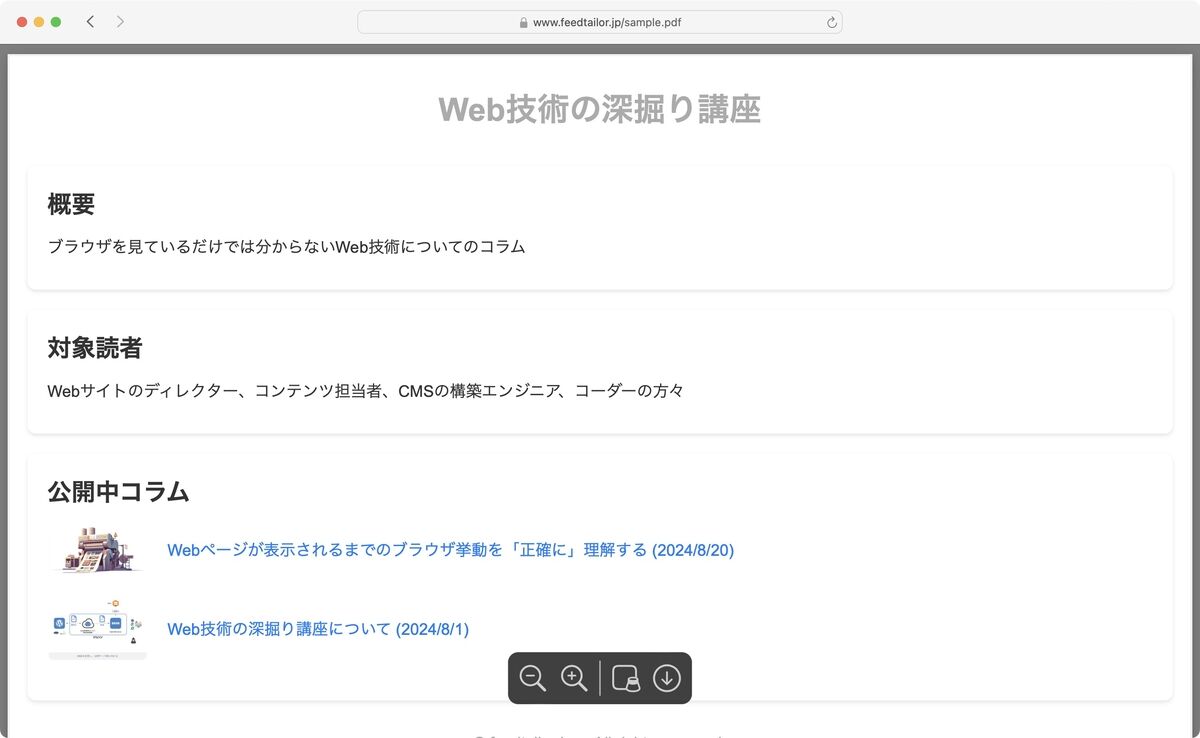
https://www.feedtailor.jp/sample.pdf
というURLがある場合、ブラウザはどう振る舞うでしょうか?
これは簡単ですね。sample.pdf のPDFがサーバ上に存在するなら、ブラウザは sample.pdf のファイルをサーバから受け取り、それを表示して作業としては完了です。上記の(1)で終わります。
画像や動画、CSSやJavaScriptのファイルも一緒です。直接URLを指定したら、そのファイルそのものがブラウザ上で見えますね。そう、基本的にブラウザはURLで指定された「モノ」だけを取得して表示するソフトウェアに過ぎないのです。
ただし、例外があります。
ブラウザはHTMLを受け取ると例外的挙動をする
ブラウザが特別な挙動をするのは、取得する「モノ」が主に
- HTMLファイル
- XMLファイル
この2つに該当する場合です。(※1)
もう一度ブラウザの基本動作を示します。
- (1) URLで指定された「モノ」だけを取得して表示する
- (2) その「モノ」がHTML(かXML)ファイルなら、関連するファイルも取得して反映する
HTMLファイルとXMLファイルだけは、(1)だけで終わらず(2)まで進みます。では、関連ファイルとは何でしょう?ブラウザはどうやって見つけ出すのでしょう?
ご承知の通り(1)で取得した中に明記されています。HTMLの場合、その関連ファイルが CSSファイルなら <link> タグで、画像ファイルなら <img> タグで、JavaScriptファイルなら <script>タグで表すことはよく知られています。
<link rel="stylesheet" href="/styles/style.css">
# HTMLの見た目を整えるための関連ファイル(CSS)があるぞ、とブラウザに伝えている
<script src="/js/main.js">
# HTMLを表示した後に実行すべき関連ファイル(JavaScript)があるぞ、とブラウザに伝えている
<img src="/images/picture.jpg">
# HTMLの表示中に差し込むべき関連ファイル(画像ファイル)があると、とブラウザに伝えているまた、XML(通常意識するのはサイトマップぐらいでしょう)の関連ファイルとしては、xsltが知られています。
<?xml-stylesheet type="text/xsl" href="transform.xslt"?>
# XMLの見た目を整えるための関連ファイル(XSLT)があるぞ、とブラウザに伝えているこのように、HTMLやXMLの取得&表示後に、関連ファイルを自動取得して後から反映を行うわけです。そして、関連するファイルがあればあるだけ(2)を繰り返します。
よくある「Webページの表示がおかしい」とか「崩れている」という状態は、(2)の関連ファイルが正しく取得できていないことが原因です。HTMLは関連ファイルの数が膨大(HTMLファイルが1に対して関連ファイルが50とか100とかが普通にある)なので、数が多いぶん問題が発生し易いのです。
PDFの中身が一部おかしいとか、画像の一部だけおかしいとか、ありませんよね?それはPDFを取得して表示、画像を取得して表示、という(1)しかやってないからです。関連ファイルという概念がなく、おかしいならファイルそのものがもうおかしい、だから差し替えて終了です。
ですが、HTMLは違います。関連ファイルが膨大にあって、1ページ表示するだけで数十個のファイルを取得しまくって処理します。だから、トラブルが起りやすいし、全体像が見えにくいし、問題が起った時に特定しにくいのです。
関連ファイルの話で言うと、HTML中に
<a href="next.html">次のページ</a>このように記述された next.html というHTMLファイルは、原則的に関連ファイルとは見なされません。今表示しているHTMLに関連するファイルではなく、独立した別のHTMLファイルであると見なされるからですね。従って、自動的に取得しにいくことはありません。(ただHTMLを特別に関連ファイルと見なし自動取得しにいくケースもあります。また別の機会に紹介します)
以上、我々がブラウザにURLを入力した時、ブラウザが何をしているかを解説しました。ブラウザの挙動という観点では、HTMLファイルは例外的な扱いを受けます。HTMLファイルの取得&表示をしただけでは終わらず、HTML中に記載ある関連ファイルを自動取得した上でHTMLの表示に後から反映しようとするのです。
次回以降で、そのブラウザ挙動の様子をつぶさに見れる方法を紹介します。普段目にしないWeb技術を見ることができれば、Webサイトがブラウザにどう扱われるか真の姿が見えてきます。
※1 ブラウザにもよるため厳密に書けば他にもありますが、基本的には上記理解で問題ありません